2026

Do LLMs Model Human Linguistic Variation? A Case Study in Hindi-English Verb Code-Mixing
Mukund Choudhary#, Madhur Jindal, Gaurja Aeron, Monojit Choudhury (# corresponding author)
EACL 2026
the choice of using English nouns/verbs in do-verb constructions in Hindi sentences instead of Hindi ones is governed by a bunch of shared constraints between native speakers. some verbs are extremely easy to mix in, others are disagreed upon. given that LLMs are publicised as capable models of data rich languages, English and Hindi, and Hinglish should be fairly represented. however we find that native speaker variation is not reflected in LLM perplexities of various sizes and training language mixes, thus making them not ready to use for modeling human linguistic intuition as well. we use this to start talking about the area and also as a first contribution to model more linguistic variation studies on.

Nanda Family: Open-Weights Generative Large Language Models for Hindi
Aaryamonvikram Singh#, ..., Monojit Choudhury, ..., Mukund Choudhary, ..., Preslav Nakov (# corresponding author)
EACL 2026
LLMs for Hindi are just starting to grow, and are lacking quality especially for culturally grounded tasks. we help fix this for Hindi with Nanda (10B and 87B), adapting Llama-3/3.1 through three key moves: (1) extending the tokenizer with 20% Hindi-specific tokens to halve tokenization fertility while keeping English efficient, (2) Hindi-first parameter-efficient continuous pretraining on 65B tokens covering Devanagari, code-mixed, and romanized Hindi, and (3) bilingual instruction and safety alignment on culturally grounded data. Nanda models beat comparable open-weights and show top-tier safety performance. the takeaway: smart tokenizer design, data curation, and expansion-based continual pretraining can get you capable and safe LLMs for resource-poor languages without sacrificing English performance.
2025
Number-Feature and Noun Representation Distortion in Hindi Sentences
Gaurja Aeron#, Mukund Choudhary, Himanshu Yadav (# corresponding author)
ACCS 2025
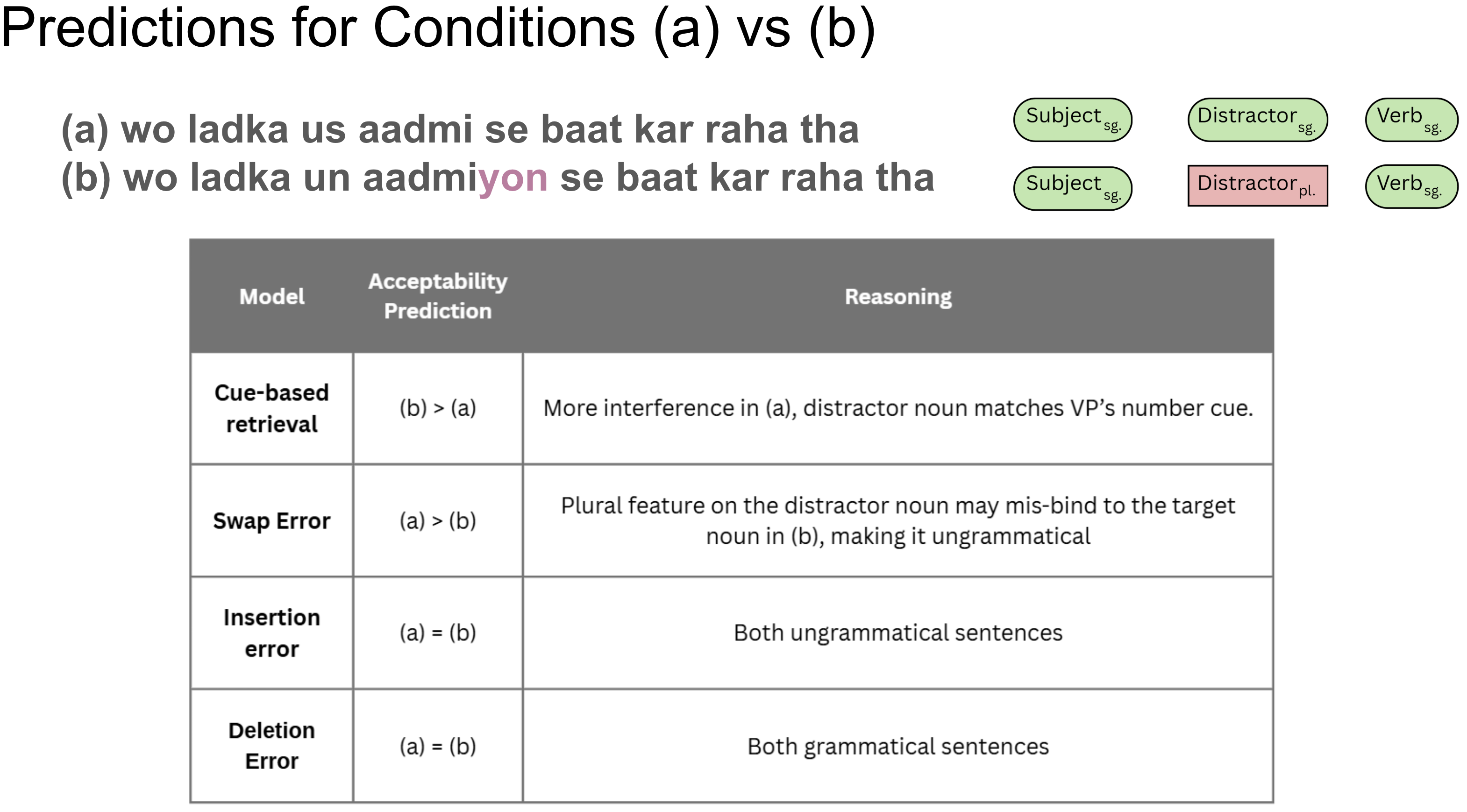
real-time Hindi sentence comprehension isn’t just about retrieving the right chunks from memory, it’s also about how those chunks distort in our memory while sitting there. we test the representation distortion hypothesis, which says memory doesn’t store sentence parts faithfully; stuff like number features or noun roles can get deleted or swapped to make ungrammatical sentences, grammatical. we design experiments with agreement mismatches and case-marker swaps, and find that deletion errors, especially of number features, are common, and that noun-case distortions make semantically weird sentences feel more okay. studying this in Hindi (which is linguistically different than English in representing case, number, etc.) helps generalise findings and bring out nuances in the field.
unveiLing: What Makes Linguistics Olympiad Puzzles Tricky for LLMs?
Mukund Choudhary#, KV Aditya Srivatsa, Gaurja Aeron, ..., Ekaterina Kochmar, Monojit Choudhury (# corresponding author)
COLM 2025
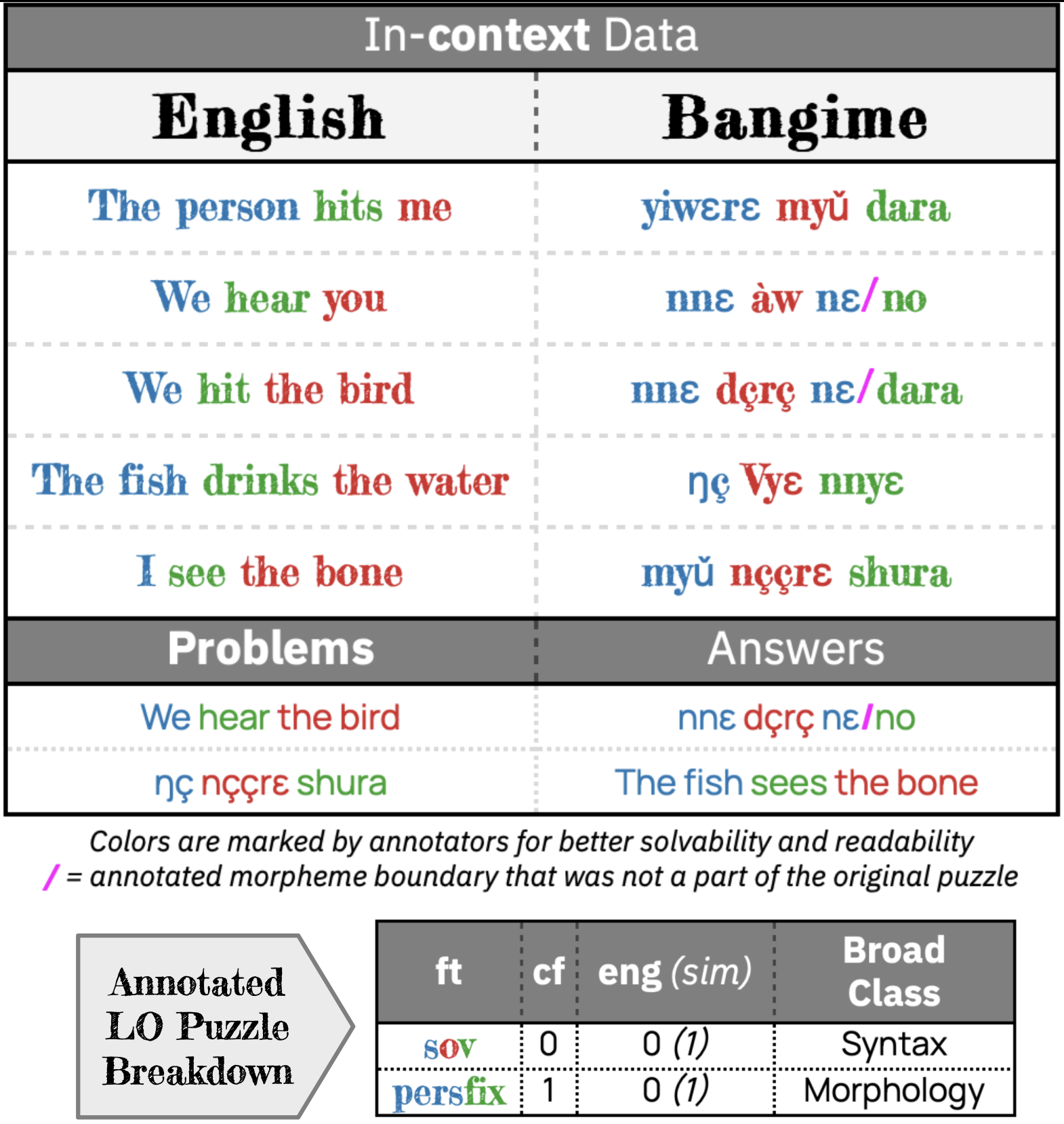
for models that are large and are supposed to be good at language, they are kind of bad at human linguistics. we see that LO puzzles which are basic reasoning puzzles based on linguistic phenomena in extremely low resourced languages, but are exhaustive and completely solvable for highschoolers by design, are a challenge for LLMs. this is because they are bad at pattern matching, reasoning, etc. but more concretely we find that linguistic factors like morpholigcal complexity, closeness to English, and amount of evidence to understand how a linguistic feature (as per WALS) works, are highly correlated to poor performance.
2023
Neural Models for Factual Inconsistency Classification with Explanations
Tathagata Raha#, Mukund Choudhary, Abhinav S Menon, Harshit Gupta, KV Aditya Srivatsa, Manish Gupta, Vasudeva Varma (# corresponding author)
ECML PKDD 2023
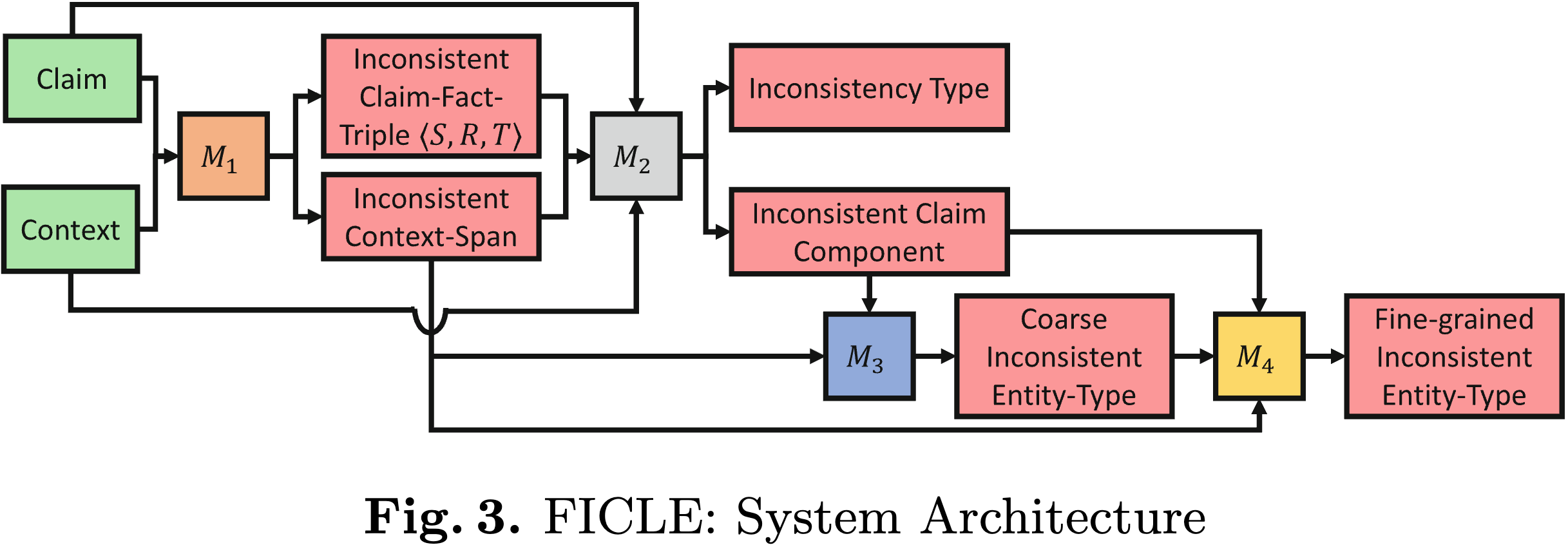
factual consistency is crucial for all kinds of language generation tasks: summarization, QA, dialogue, LMs, etc. but detecting why something is factually off, without any external knowledge base, is still barely studied. we fix that by defining five concrete types of factual inconsistencies using linguistic theory, and contribute FICLE, an 8K-sample dataset of claim-context pairs annotated with inconsistency type, span, and entity mismatches (both coarse and fine). we train a four-part neural pipeline to detect inconsistent spans, identify the type, and flag the exact entity issues, if any. DeBERTa leads the pack with 87% weighted F1 on type prediction. the takeaway: not only can we catch factual errors without a KB, we can explain how they are bad, making factuality checks more usable and interpretable.

CoPara 🥥: The First Dravidian Paragraph-level n-way Aligned Corpus
E Nikhil#, Mukund Choudhary, Radhika Mamidi (# corresponding author)
RANLP: DravidianLangTech 2023
We present CoPara, the first publicly available paragraph-level (n-way aligned) multilingual parallel corpora for Dravidian languages. The collection contains 2856 paragraph/passage pairs between English and four Dravidian languages. We source the parallel paragraphs from the New India Samachar magazine and align them with English as a pivot language. We do human and artificial evaluations to validate the high-quality alignment and richness of the parallel paragraphs of a range of lengths. To show one of the many ways this dataset can be wielded, we finetuned IndicBART, a seq2seq NMT model on all XX-En pairs of languages in CoPara which perform better than existing sentence-level models on standard benchmarks (like BLEU) on sentence level translations and longer text too. We show how this dataset can enrich a model trained for a task like this, with more contextual cues and beyond sentence understanding even in low-resource settings like that of Dravidian languages. Finally, the dataset and models are made available publicly at CoPara to help advance research in Dravidian NLP, parallel multilingual, and beyond sentence-level tasks like NMT, etc.
Pseudowords: Generatucing, Evaluadating, and their Impactfluence
Mukund Choudhary#, Bapi Raju Surampudi, Dipti Misra Sharma (# corresponding author)
Masters Thesis @ IIIT Hyderabad 2023
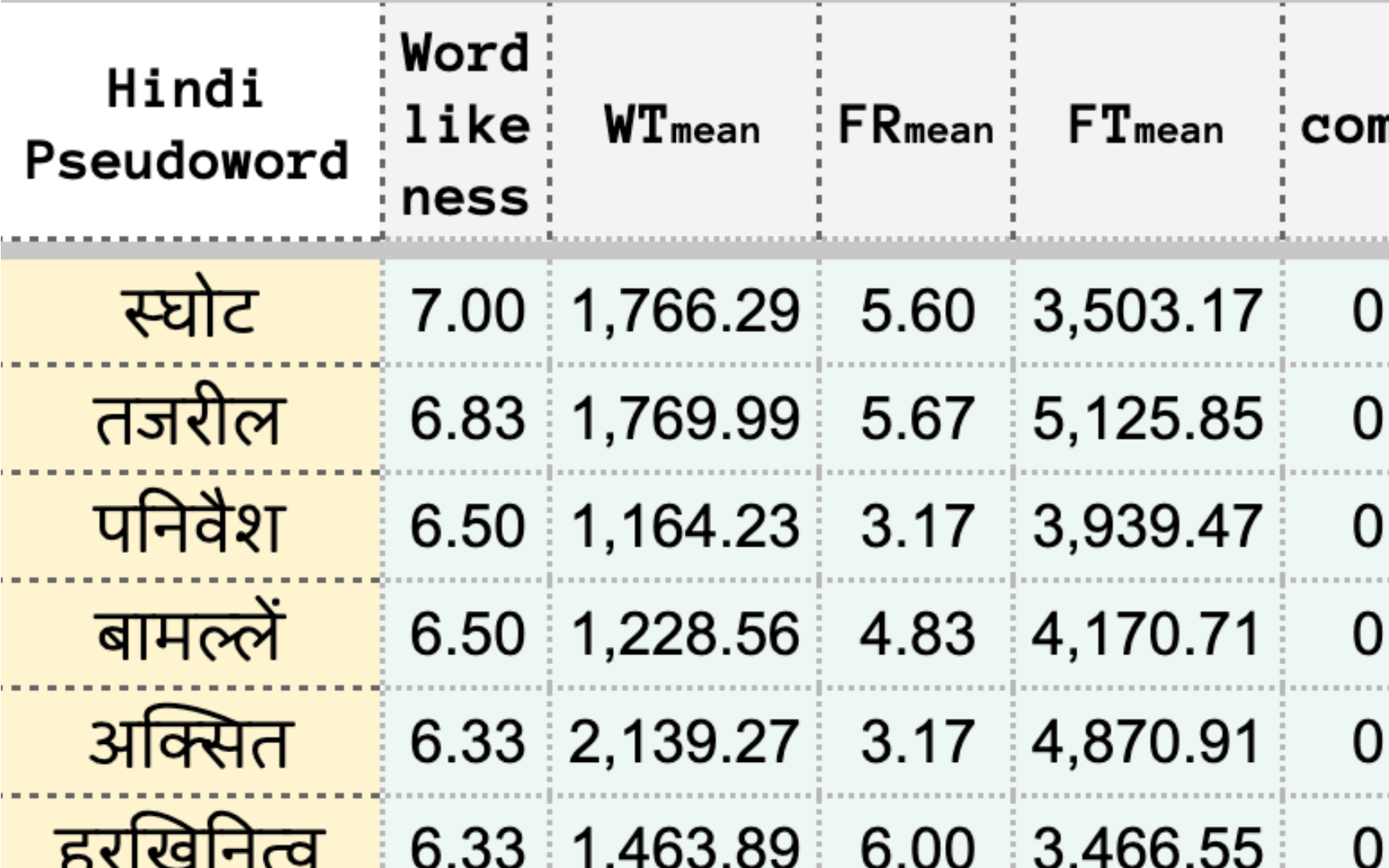
pseudowords are weird, they sound real, but mean nothing, and don’t translate across languages. we explore how to automatically generate and evaluate pseudowords in a language-agnostic way, to help universal clinical and psycholinguistic use. we build a reusable pipeline (publicly released) which only uses a basic LSTM and an IPA dictionary of the language, generate Hindi and English pseudowords, and stitch together a cognitive science based, reproducible framework for human evaluation. this leads to Soodkosh, the first mostly automatically generated Hindi pseudoword dataset with a lightweight experiment design to collect psycholinguistic features from native judgements. finally, we show their utility: (1) pseudowords help measure perceived password strength vs. memorability, and (2) we test if swapping them in helps LMs classify aphasia, but find that pseudowords can’t be directly replaced, even if they’re subtly used.
2022

NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Kaustubh Dhole#, ..., KV Aditya Srivatsa*, Mukund Choudhary*, ... (* equal contribution, # corresponding author)
NEJLT 2022
Contributed Butter Fingers Pertubation For Indian Langauges to this paper. Abstract: Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository.
2021
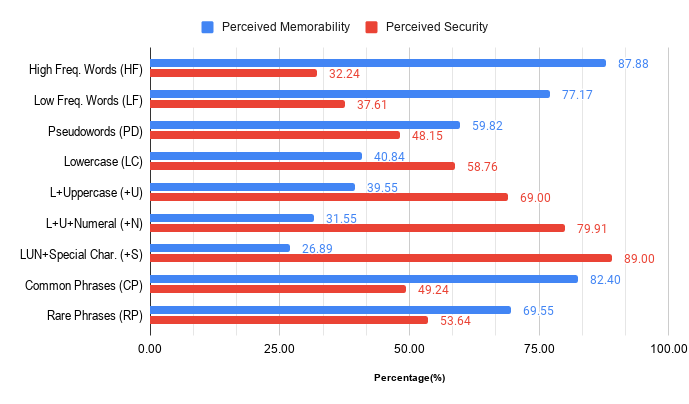
Is Convenient Secure? Exploring the impact of Metacognitive beliefs in password selection
Mukund Choudhary#, KV Aditya Srivatsa, Ishan Sanjeev Upadhyay, Priyanka Srivastava (# corresponding author)
CogSci 2021
Recently, there has been research on what factors influence a user’s password setting practices, which include various types of emotions such as anger, risk-taking tendencies, etc. However, research has shown that factors such as memorability and perceived memorability have a greater influence on password choice. Some recent research has shown a negative correlation between the perceived memorability and the perceived security of passwords, particularly passphrases (that are technically more secure). However, it is unclear whether this effect can be extended to groups with good experiences with digital spaces (IT professionals, entrepreneurs, etc.). Furthermore, it has not been determined whether random, uncommonly-worded, or complex structure passphrases would also maintain the correlation, as opposed to relatively less secure, common/simple passphrases. This study examines this problem using a diverse demographic and different categories of passphrases.